
Decision Tree Theory
A Decision Tree is a supervised learning algorithm used for classification and regression tasks. It splits the data into branches based on conditions or rules derived from the input features. The process continues until it reaches “leaf nodes,” which represent the final decision or output.
Key Concepts
- Root Node: Represents the entire dataset and splits into child nodes based on the best attribute.
- Decision Nodes: Intermediate nodes that split further into other nodes.
- Leaf Nodes: Represent the output class or final prediction.
- Splitting Criteria:
- Gini Impurity: Measures the impurity of a split. A lower value indicates a better split.
- Entropy: Used in the Information Gain calculation, representing the disorder or randomness in data.
- Variance Reduction: Used for regression trees to minimize the variance in outputs.
Here is the decision tree diagram for the “Weather and Play Tennis” example. It shows:
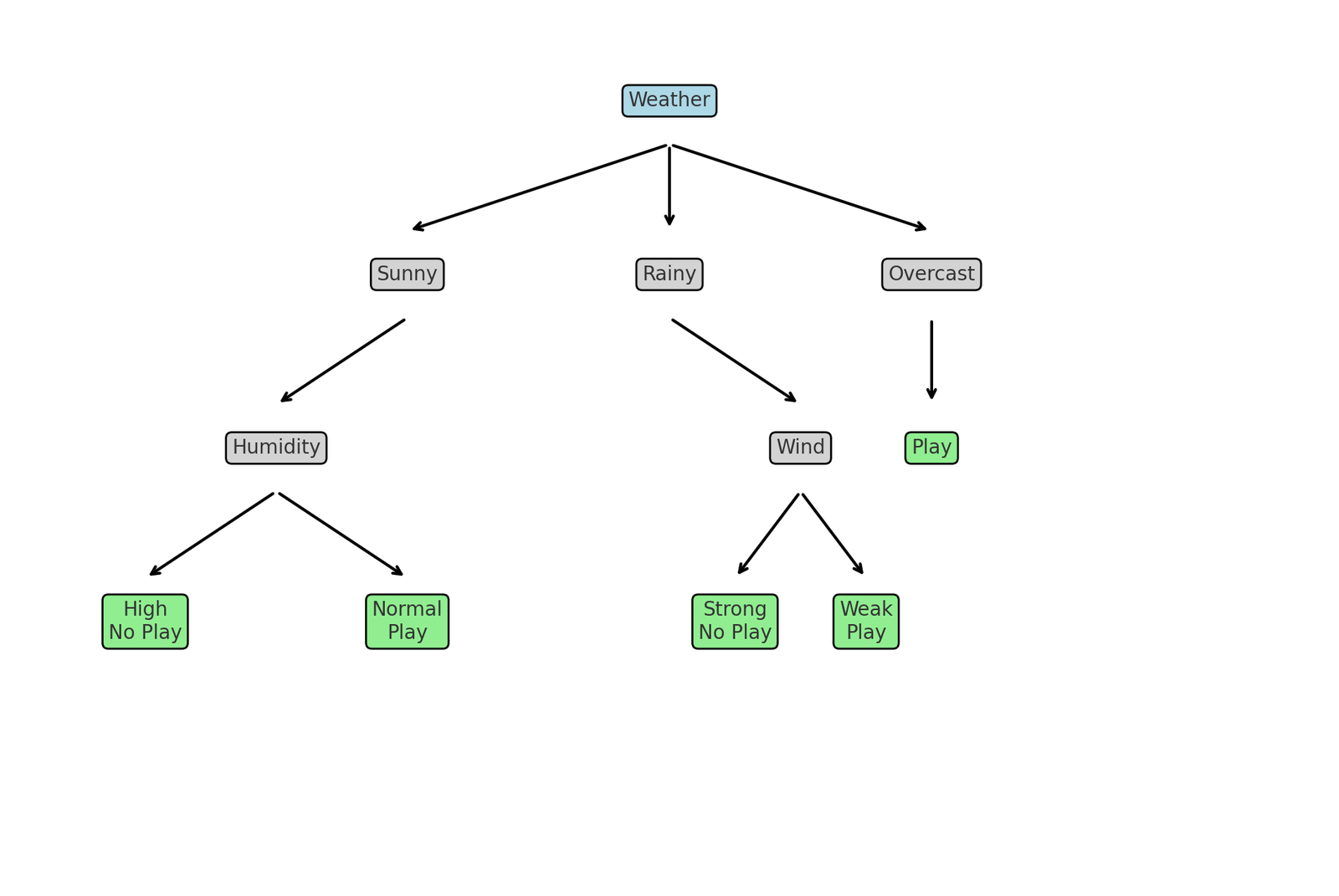
- Root node: Weather (Sunny, Overcast, Rainy)
- Conditions: Humidity (for Sunny) and Wind (for Rainy)
- Outcomes: Whether to play or not based on these conditions.
Advantages
- Easy to interpret and visualize.
- Handles both numerical and categorical data.
- No need for feature scaling.
Disadvantages
- Prone to overfitting if not pruned or limited in depth.
- Sensitive to small variations in the data.