
Titanic Dataset Overview
The Titanic dataset provides information about passengers aboard the Titanic. The key columns are:
- PassengerId: Unique ID for each passenger.
- Survived: Binary variable indicating survival (1 for survived, 0 for did not survive).
- Pclass: Passenger class (1st, 2nd, or 3rd class).
- Name: Passenger name.
- Sex: Gender (male or female).
- Age: Age in years.
- SibSp: Number of siblings or spouses aboard the Titanic.
- Parch: Number of parents or children aboard the Titanic.
- Ticket: Ticket number.
- Fare: Fare paid by the passenger.
- Cabin: Cabin number (if available).
- Embarked: Port of embarkation (C = Cherbourg, Q = Queenstown, S = Southampton).
The goal is to predict Survived using other features.
Python Code to Apply Decision Tree
Here’s the code to preprocess the dataset and apply a decision tree classifier:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# Load Titanic dataset
# Replace 'your_dataset.csv' with the path to your Titanic dataset
data = pd.read_csv('your_dataset.csv')
# Data Preprocessing
# Drop irrelevant columns
data = data.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'])
# Handle missing values
data['Age'].fillna(data['Age'].median(), inplace=True)
data['Embarked'].fillna(data['Embarked'].mode()[0], inplace=True)
# Encode categorical variables
data = pd.get_dummies(data, columns=['Sex', 'Embarked'], drop_first=True)
# Splitting features and target
X = data.drop('Survived', axis=1)
y = data['Survived']
# Split dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a Decision Tree Classifier
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# Predict on the test set
y_pred = clf.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# Plot the decision tree
plt.figure(figsize=(15, 10))
plot_tree(clf, feature_names=X.columns, class_names=['Did not Survive', 'Survived'], filled=True)
plt.show()
Explanation:
- Preprocessing:
- Irrelevant columns (e.g.,
PassengerId,Name) are dropped. - Missing values in
AgeandEmbarkedare filled with appropriate statistics. - Categorical variables (
Sex,Embarked) are encoded as numeric.
- Irrelevant columns (e.g.,
- Model Training: A decision tree is trained using the
DecisionTreeClassifierfromsklearn. - Evaluation: The model’s accuracy and classification report are printed, and the tree structure is visualized.
What is Classification Report
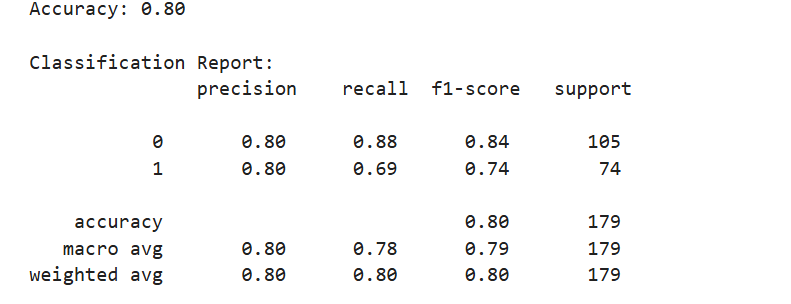
The classification report provides various metrics that evaluate the performance of a classification model, in this case, a decision tree applied to the Titanic dataset. Let’s break it down:
1. Precision:
- Precision is the ratio of correctly predicted positive observations to the total predicted positives.
- For class 0 (did not survive), the precision is 0.80, meaning that out of all instances where the model predicted “did not survive,” 80% were correct.
- For class 1 (survived), the precision is also 0.80, meaning 80% of the predictions for “survived” were accurate.
Formula for Precision:
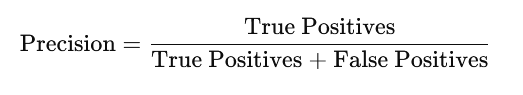
2. Recall:
- Recall (or Sensitivity) is the ratio of correctly predicted positive observations to all observations in the actual class.
- For class 0 (did not survive), the recall is 0.88, meaning that out of all the actual “did not survive” instances, the model correctly identified 88% of them.
- For class 1 (survived), the recall is 0.69, meaning that the model identified 69% of the actual survivors.
Formula for Recall:

3. F1-Score:
- The F1-score is the weighted average of precision and recall. It takes both false positives and false negatives into account, making it a useful metric when you have class imbalance.
- For class 0 (did not survive), the F1-score is 0.84, which is a balanced metric considering both precision and recall.
- For class 1 (survived), the F1-score is 0.74, reflecting a tradeoff between precision and recall.
Formula for F1-Score:
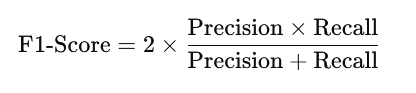
4. Support:
- Support is the number of actual occurrences of the class in the dataset. For instance:
- Class 0 (did not survive): There are 105 instances of this class in the test data.
- Class 1 (survived): There are 74 instances of this class in the test data.
5. Accuracy:
- The accuracy of the model is 0.80, meaning the model correctly predicted the survival status of 80% of the test samples. This is a high-level overview of performance.
6. Macro Average:
- The macro average is the average of the precision, recall, and F1-score across all classes. It gives equal weight to each class, regardless of their support (size).
- Precision (macro avg): 0.80, the average precision for both classes.
- Recall (macro avg): 0.78, the average recall across both classes.
- F1-score (macro avg): 0.79, the average F1-score for both classes.
7. Weighted Average:
- The weighted average takes into account the number of instances of each class (support) and computes a weighted average of precision, recall, and F1-score.
- Precision (weighted avg): 0.80
- Recall (weighted avg): 0.80
- F1-score (weighted avg): 0.80
- The weighted average helps provide a more representative score when the dataset is imbalanced.
Summary of the Report:
- The model is quite good at predicting whether a passenger did not survive (class 0) with high recall (88%).
- However, it performs less well in predicting whether a passenger survived (class 1) with lower recall (69%) and a slightly lower F1-score (0.74).
- The overall accuracy of the model is 80%, which indicates good predictive performance.
In short, the model is effective in identifying non-survivors but could benefit from improvements in predicting survivors, especially given the imbalanced dataset where more passengers did not survive.