
Fashion-MNIST is a dataset of Zalando’s article images consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image, associated with a label from 10 classes.
In the Fashion-MNIST dataset (like the original MNIST dataset for digits), the range 0 to 255 represents the pixel intensity values of the grayscale images:
- 0: Represents black (the lowest intensity of light, i.e., no brightness).
- 255: Represents white (the highest intensity of light, i.e., maximum brightness).
Each image in the dataset is 28×28 pixels, and the pixel values are stored as integers between 0 and 255.
Why is this range important?
- It defines the level of detail in the grayscale image.
- Models often work better if pixel values are normalized, so they are typically rescaled to a range like 0 to 1 or -1 to 1 during preprocessing. For example: Normalized Value=Pixel Value255\text{Normalized Value} = \frac{\text{Pixel Value}}{255} This step improves training stability and convergence in machine learning models.
Example:
A pixel with a value of:
- 0 means it is completely black.
- 128 means it is a medium gray.
- 255 means it is completely white.
So the range 0-255 simply represents the intensity of brightness at each pixel in the Fashion-MNIST dataset images.
Code Explanation
from keras.models import Sequential
from keras.layers import Flatten, Dense, Activation1. from keras.models import Sequential
This imports the Sequential class from Keras. A Sequential model is a linear stack of layers, where each layer feeds its output to the next layer. It’s the simplest way to build a neural network in Keras.
2. from keras.layers import Flatten, Dense, Activation
This imports the following layer types from Keras:
Flatten: A layer that flattens multi-dimensional input (like a 2D image) into a 1D vector. For example, a 28×28 image becomes a 784-dimensional vector.Dense: A fully connected (or dense) layer, where every input neuron is connected to every output neuron. This is a core building block of neural networks.Activation: A layer that applies an activation function (like ReLU, sigmoid, softmax, etc.) to introduce non-linearity to the model.
Purpose of the Code
This code is preparing to define a feedforward neural network with the following steps:
Sequential: To create a stack of layers.Flatten: To flatten input data (e.g., 2D image arrays) into a vector that can be passed to fully connected layers.Dense: To add fully connected layers, which are essential for mapping inputs to outputs.Activation: To add activation functions, which are critical for non-linear transformations.
Example of How This Could Be Used
from keras.models import Sequential
from keras.layers import Flatten, Dense, Activation
# Create a Sequential model
model = Sequential()
# Add layers
model.add(Flatten(input_shape=(28, 28))) # Flatten 28x28 input into a vector of 784
model.add(Dense(128)) # Add a fully connected layer with 128 neurons
model.add(Activation('relu')) # Add ReLU activation for non-linearity
model.add(Dense(10)) # Add a fully connected output layer with 10 neurons (for 10 classes)
model.add(Activation('softmax')) # Add softmax activation for output probabilities
# Summary of the model
model.summary()
What the Layers Do
Flatten: Converts input data from shape(28, 28)to(784,). Essential for image inputs.Dense(128): Adds a dense (fully connected) layer with 128 neurons. These neurons learn features from the input.Activation('relu'): Adds the ReLU activation function. ReLU helps the network learn complex patterns by introducing non-linearity.Dense(10): Adds another dense layer with 10 neurons, one for each class in a classification problem (e.g., Fashion-MNIST has 10 categories of clothing).Activation('softmax'): Applies the softmax activation function, which converts the 10 outputs into a probability distribution for classification.
Model Summary
When run, the model.summary() method will show the structure of the network, including the number of parameters to be trained in each layer. This example creates a simple model for tasks like Fashion-MNIST classification.
You will get output of Model Summary
This model summary provides an overview of the architecture of your neural network, showing the structure, the number of parameters to train, and the shape of the data as it flows through each layer. Let’s break it down:
Key Components of the Table
- Layer (type):
- Lists the name and type of each layer in the model.
- Example:
flatten (Flatten)is the first layer in the model, anddense (Dense)represents fully connected layers.
- Output Shape:
- The shape of the output produced by each layer.
- It tells how the data gets transformed as it flows through the network.
- Example:
(None, 784)means the Flatten layer outputs a 784-dimensional vector for each sample. TheNoneindicates the batch size is dynamic and not fixed.
- Param #:
- The total number of trainable parameters in each layer.
- Parameters include weights and biases that the model learns during training.
- Example: The first Dense layer has 78,500 parameters to train.
Layer-by-Layer Breakdown
1. flatten (Flatten)
- Output Shape:
(None, 784)- Takes input data (e.g., a 28×28 image) and flattens it into a 1D vector of 784 features per sample.
- Param #:
0- This layer has no trainable parameters; it only reshapes the data.
2. dense (Dense) (First Fully Connected Layer)
- Output Shape:
(None, 100)- Maps the 784 features from the Flatten layer to 100 neurons in this layer.
- Param #:
78,500
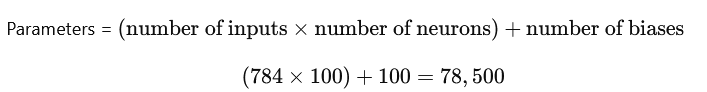
3. dense_1 (Dense) (Second Fully Connected Layer – Output Layer)
- Output Shape:
(None, 10)- Maps the 100 features from the previous Dense layer to 10 neurons, one for each output class (e.g., for classification problems with 10 categories).
- Param #:
1,010
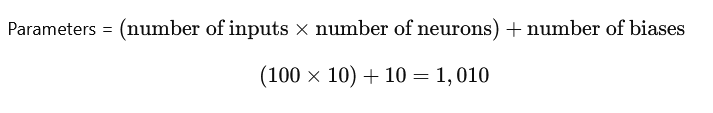
Totals
- Total Params:
79,510- The total number of trainable parameters in the model (weights + biases).
- These parameters will be updated during training to minimize the loss function.
- Trainable Params:
79,510- All the parameters in this model are trainable, meaning they will be adjusted during backpropagation.
- Non-trainable Params:
0- There are no fixed parameters in this model (e.g., no frozen layers).
What This Means
- Your model has 2 trainable layers (Dense layers) with a total of 79,510 parameters.
- The Flatten layer preprocesses the input (e.g., an image) to make it suitable for the Dense layers.
- The Dense layers perform the actual computation and mapping from input features to the final output.
- This model is relatively small and well-suited for tasks like image classification on datasets like Fashion-MNIST.